메모리 구조에 대해 잘 모른다면 다음 포스팅을 보고 오는 것을 추천한다.
[C++] 클래스의 멤버가 저장되는 영역 및 메모리 차지
클래스 사용 도중 헷갈리던 내용이 있어서 정리함. 함수 내에서 임시로 객체를 생성할 때 사용 용도에 따라 비효율적인 부분이 있는지 헷갈려서 instance 생성 시 각 멤버들이 어떻게 메모리를 차�
woo-dev.tistory.com
구조체 및 클래스는 실제로 메모리 상에 어떻게 저장될까?
먼저 다음과 같은 구조체를 생각해보자.
struct Foo
{
uint32_t mUInt1; // 32비트
uint8_t mUint2; // 8비트
int32_t mInt1; // 32비트
bool mBool1; // 8비트
char* mCharPtr; // 32비트
};위 구조체의 크기는 모든 비트 수를 합한 14바이트(112bit)라 생각할 수 있지만, 실제론 20바이트이다.
위 구조체는 다음과 같이 1번이 아닌 2번과 같이 저장된다.

즉 4바이트 미만의 변수들은 패딩(padding)이라는 NULL과 비슷한 데이터가 덧붙여졌다. 위 구조체는 20바이트의 크기 중 6바이트의 크기가 패딩 데이터로 낭비되고 있다.
실제로 확인해보면 다음과 같이 assert에 걸리지 않으며, 1바이트 메모리에 3바이트의 쓰레기 값이 붙은 것을 볼 수 있다. 이는 컴파일러가 추가해준 값이다.


이처럼 컴파일러가 4바이트로 정렬을 해주는 이유는 모든 데이터 타입엔 메모리 혹은 바이트 정렬(alignment)이라는 속성이 있는데, CPU가 메모리를 효율적으로 읽고 쓰기 위해선 해당 속성을 지켜야 하기 때문이다.
지키면 무슨 이점이 있기에?
CPU는 처리할 데이터를 메모리(RAM)에서 가져오는데, 이 가져오는 작업(접근)이 CPU의 속도 저하를 일으키는 큰 원인이다. 즉 CPU가 메모리에 접근하는 횟수가 많을수록 속도가 느려진다는 뜻이다. CPU가 메모리에서 데이터를 가져올 때, CPU 및 운영체제마다 다르지만 한 번에 데이터를 가져올 수 있는 크기가 보통 32비트(DWORD), 64비트(QWORD)로 정해져 있고, 이 크기는 보통 레지스터의 크기라고 생각하면 된다. (물론 CPU는 운영체제에 의해 현재 명령어를 실행할 뿐이다. 메모리에 데이터가 적재되는 동안 CPU가 놀고 있는 상황을 속도 저하라 생각하자.)
그런데 대부분의 CPU는 메모리에서 데이터를 가져올 때 메모리 정렬이 된 데이터 블록만 가져올 수 있다. 메모리 정렬의 기준은 다음과 같다.
- 1바이트 정렬 객체는 어떤 메모리 주소에도 올 수 있다.
- 2바이트 정렬 객체는 짝수인 주소에만 올 수 있다. (i.e. 16진수 주소 끝이 0, 2, 4, 8, A, C, E)
- 4바이트 정렬 객체는 4의 배수가 되는 주소에만 올 수 있다. (i.e. 주소 끝이 0, 4, 8, C)
- 16바이트 정렬 객체는 16의 배수가 되는 주소에만 올 수 있다. (i.e. 주소 끝이 0)
CPU는 위와 같은 규칙에 맞게 메모리의 데이터를 가져온다. 예를 들어, 32비트 정수 값이 다음과 같이 저장되어 있다고 생각 해보자.

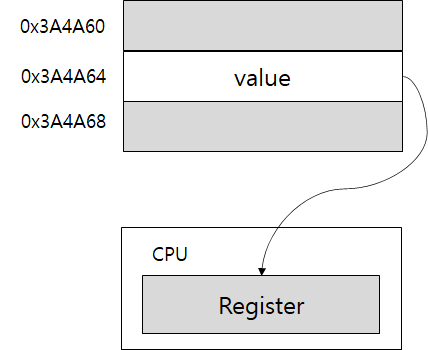
왼쪽은 0x3A4A64라는 주소의 메모리 블럭에 4바이트 값이 정렬되어 저장되어 있다. (끝 주소가 4의 배수)
반면 오른쪽은 0x3A4A60라는 주소의 메모리 블럭과 0x3A4A64라는 주소의 메모리 블럭에 나뉘어 저장되어 있다.
CPU의 메모리 컨트롤러(MC) 또는 메모리 컨트롤러 유닛(MCU)은 정렬된 값을 읽을 때 다음과 같이 곧바로 레지스터에 저장할 수 있다.
하지만 정렬되지 않은 값을 읽을 땐 다음과 같은 작업을 수행 후 레지스터에 저장한다.

값이 두 블럭에 나뉘어 있기 때문에 MCU는 우선 두 블럭을 모두 읽는다. 그 후 하나의 블럭 안에 알맞은 순서로 합쳐질 수 있도록 shift 연산을 수행하고, OR 연산하여 하나의 데이터 블록으로 레지스터에 저장한다. 어떤 CPU는 이러한 작업을 해주지 않고, 데이터 정렬이 되어있지 않다면 쓰레기 값으로 읽거나 프로그램을 강제 종료한다. 참고로 플레이스테이션2가 메모리 정렬을 엄격하게 제한한다고 한다.
처음으로 돌아가서 다시 패딩 데이터에 대한 얘기를 해보면, CPU가 위와 같은 작업을 하지 않도록 컴파일러가 패딩 데이터를 추가하여 정렬 조건을 갖추도록 하는 것이다. 다음은 처음에 보았던 메모리 구조이다. 2, 4번째 블럭은 각각 1바이트이기 때문에 컴파일러가 3바이트씩 추가해준 것이다. 하지만 한 번 생각해보면 다음과 같은 메모리 구조를 더 효율적으로 만들 수 있다.

바로 다음과 같이 1바이트 데이터를 연속으로 몰아주면 된다. 한 곳에 1바이트 데이터를 모아줌으로써 총 16바이트로 4바이트를 절약했다.

이처럼 패딩 데이터를 신경써서 구조체 및 클래스를 설계하는 습관을 들이는 것도 좋다.
참고로 이러한 정렬 조건은 구조체 또는 클래스 멤버 중 크기가 가장 큰 자료형이 기준이 된다. 예를 들어 구조체 내의 가장 큰 자료형의 크기가 4바이트라면 4바이트 정렬 조건을 따르고, 2바이트면 2바이트, 1바이트면 1바이트 정렬 조건을 따른다. 즉 다음과 같이 멤버 변수가 char 타입으로만 이루어져 있다면 패딩 데이터를 추가하지 않는다.
struct Foo
{
bool mBool1; // 8비트
bool mBool2; // 8비트
bool mBool3; // 8비트
char mChar1; // 8비트
char mChar2; // 8비트
char mChar3; // 8비트
};위 구조체의 크기는 패딩 데이터가 추가되지 않으며, 그대로 6바이트가 된다. 가장 큰 자료형의 크기가 1바이트이기 때문에 1바이트 정렬 기준만 따르면 된다.
패딩 데이터는 다음과 같이 명시적으로 사용자가 직접 추가해줘도 된다.
struct Foo
{
uint32_t mUInt1; // 32비트
int32_t mInt1; // 32비트
char* mCharPtr; // 32비트
uint8_t mUint2; // 8비트
bool mBool1; // 8비트
uint8_t pad[2]; // 16비트 패딩 데이터
};
참고: 게임 엔진 아키텍처
'C,C++ > Etc' 카테고리의 다른 글
| 스레드 관련 글 (0) | 2020.06.25 |
|---|---|
| Visual Studio C++ 17 사용하도록 설정하기 (0) | 2020.06.25 |
| [C++] 비트 연산자로 N번째 비트 변경하기 (0) | 2020.03.11 |
| [C++] 소수점 n번째 자리에서 반올림 하기 | std::round (0) | 2020.02.26 |
| [C++] 한 줄 짜리 지식 모음 (0) | 2020.01.20 |



댓글