개인적으로 학습하는 내용이라 틀린 내용이 있을 수 있습니다.
참고 도서: 개념 이해를 위한 운영체제
[스레드란?]
스레드란 프로세스보다 조금 더 구체적인 개념으로, 하나의 프로세스 내에서 실행되는 하나 또는 여러개의 작업 단위라고 볼 수 있다. 스레드는 프로세스와 유사한 속성을 가지고 있으며 다음과 같이 정의될 수 있다.
- CPU 제어의 흐름
- 실행 단위
- 한 프로세스 내부에서 스케줄링이 가능한 개체
보통 하나의 프로세스 내에 기본적으로 하나의 스레드가 존재하며, 프로세스가 실행된다 함은 프로세스 내부의 스레드의 흐름을 의미한다. 이처럼 하나의 프로세스에 하나의 스레드만 허용하는 환경을 싱글 스레드 환경이라 하며, 싱글 스레드 환경에선 프로세스와 스레드를 크게 구분 짓지 않아도 된다. 하지만 요즘 대부분은 하나의 프로세스 내에 두 개 이상의 스레드가 존재하는 멀티 스레드 환경이기 때문에 프로세스와 스레드를 구분하고 이해하는 것은 중요하다. 스레드 또한 프로세스와 같이 생명 주기를 가지고 다양한 상태를 가진다. 이는 잠시 후 알아보도록 한다.
[멀티 스레딩]
하나의 프로세스 내에 여러개의 스레드를 허용하는 환경을 멀티 스레딩 환경이라 한다. 멀티 스레딩을 지원하는 운영체제에선 프로세스가 아닌 스레드 단위로 스케줄링을 하여, 스레드에 CPU를 할당한다. 하나의 프로세스 내의 여러 스레드들은 프로세스에게 할당된 자원을 공유한다. 때문에 프로세스에 비해 스레드를 관리하는 데 드는 비용(정보량)은 훨씬 적다. 때문에 스레드 간의 context switch 로 인한 오버헤드는 프로세스간의 전환 오버헤드보다 훨씬 적다.
다음은 두 스레드가 code(text)와 data 영역을 공유하는 것을 표시한 그림이다. 스레드는 프로세스의 자원을 공유하지만, 하나의 영역(scope) 내에서 두 스레드가 각자 실행하는 곳이 다르므로 서로 다른 스택 포인터를 가지고 있다. 즉 스택 영역은 공유하지 않고 자신(스레드)만의 고유한 영역을 가진다는 의미다.

[다중 프로그래밍과 멀티 스레딩의 차이]
다중 프로그래밍은 두 개 이상의 프로세스를 번갈아 가며 실행하는 것이고, 멀티 스레딩은 하나의 프로세스 내에서 여러 스레드를 번갈아가며 실행하는 것이다. 좀 더 쉽게 말하면, 다중 프로그래밍은 2개 이상의 서로 다른 작업장에서 왔다 갔다 하면서 작업을 하는 것이고, 멀티 스레딩은 하나의 작업장에서 여러 작업을 번갈아가면서 하는 것이다.
[스케줄링(Scheduling)]
메모리에 적재된 프로그램을 CPU가 실행할 수 있도록, 운영체제로 하여금 프로세스 또는 스레드에 CPU를 할당하는 것을 스케줄링이라 한다. 스케줄러는 제한된 자원을 여러 프로세스가 효율적으로 사용하도록 다양한 정책(policy)을 가지고 CPU를 할당한다. 여기서 정책이란 어떤 프로세스 또는 스레드에게 어떤 순서로 또는 어떤 기준으로 CPU를 할당할지를 결정하는 방법이다. 참고로 프로세스 스케줄링과 스레드 스케줄링은 할당 대상만 다를 뿐 방식은 동일하다. 여기선 프로세스 스케줄링을 기준으로 설명한다.
프로세스 스케줄러는 프로세스 선택 기준을 정하는 정책 부분과 선택된 프로세스에게 CPU를 할당하는 디스패처(dispatcher) 부분으로 구성된다. 또한 이전 포스팅에서 설명했듯이 준비 상태의 프로세스에만 CPU를 할당할 수 있는데, 이처럼 준비 상태의 프로세스가 대기하는 공간을 준비 큐(ready queue)라 한다. 즉, 프로세스 스케줄링은 준비 큐에 들어 있는 여러 프로세스 중 정책에 따라 하나의 프로세스를 선택하여 CPU를 할당하는 행위를 말한다.
[선점과 비선점]
스케줄링엔 우선 크게 선점(preemptive)과 비선점(non-preemptive) 방식으로 나뉜다. 선점 방식이란 실행 중인 프로세스가 강제적으로 실행권을 빼앗기는 것이고, 비선점 방식은 실행 중인 프로세스가 자신의 실행권을 자발적으로 내려놓는 것이다. 쉽게 이해하기 아래의 그림을 보자.

우선 비선점 방식은 1번과 2번의 상황에서 일어날 수 있다. 1번의 경우라면 할당된 시간 내에 작업을 완료했기 때문에 자발적으로 실행 상태에서 벗어나 종료되는 경우이고, 2번은 입출력처럼 운영체제의 개입이 필요하여 자발적으로 CPU로부터 벗어나는 경우이다.
선점 방식은 3,4,5번의 경우에서 일어날 수 있는데, 3번의 경우는 CPU 할당 시간의 초과로 인해 하던 작업을 완전히 끝내지 못하고 준비 상태로 돌아가는 것이다. 4번은 입출력 및 인터럽트 처리 완료로 인해 대기 중이던 프로세스가 강제로 준비 상태로 돌아가는 경우이다. 5번은 새로운 프로세스가 생성되는 경우인데, 만약 새로운 프로세스가 현재 실행 중인 프로세스보다 우선 순위가 높을 경우 새 프로세스로 강제 교체되기 때문이다. 이외에도 사실 1번과 2번에서도 선점 방식의 스케줄링은 발생할 수 있다. 예를 들면 처리할 수 없는 에러로 인해 실행 상태의 프로세스를 강제로 종료하는 경우이다. 결과적으로 선점 방식은 이름 그대로 강제적으로 CPU 사용권을 빼았는 것이고, 비선점 방식은 자발적으로 CPU 할당을 내려놓는 경우이다.
[스케줄링 정책]
프로세스의 효율적인 순환을 위해 다양한 스케줄링 정책이 존재한다. 스케줄링 정책은 다음과 같은 요소들을 고려하여 설계된다.
- CPU 이용률: 주어진 시간에 대한 CPU 사용 시간
- 처리율: 단위 시간당 처리된 프로세스 개수
- 반환시간: 프로세스가 생성된 후 종료될 때 까지 소요된 시간
- 대기시간: 프로세스가 준비 상태에서 소요된 시간
- 응답시간: 어떤 사건이 발생한 후 첫 번째 응답이 나오는 데 소요된 시간
위의 요소 중 CPU 이용률과 처리율을 최대로 하고 나머지를 최소로 하는 것이 가장 좋다. 하지만 모든 요소를 최적화할 순 없으므로 필요 시스템마다 다르게 설계하여 사용한다. 여러 스케줄링 정책이 존재하지만 여기선 다음과 같은 3가지 정책만 소개한다.
- 선입 선처리 스케줄링(First-Come First-Served)
- 순환 처리 스케줄링(Round-Robin)
- 다단계 피드백 큐 스케줄링(multi-level feedback queue)
[선입 선처리 스케줄링(FCFS)]
스케줄링은 준비 큐에 등록된 여러 프로세스 중 하나를 선택하는 과정이라 했다. FCFS 스케줄링은 큐에 등록된 순서 그대로 프로세스를 처리하는 가장 기본적인 정책이다. 주의할 점은 프로세스가 생성된 순서가 아닌 준비 큐에 등록된 순서이다. 해당 정책은 순서대로 처리하므로 실행 중인 프로세스가 다른 프로세스에 의해 선점될 수 없다. 따라서 FCFS 스케줄링은 대표적인 비선점 방식의 스케줄링이다. 다음과 같이 준비 큐에 3개의 프로세스가 순서대로 저장되어 있다고 생각해보자.
| 프로세스 | CPU 사용시간(초) |
| P1 | 16 |
| P2 | 6 |
| P3 | 3 |
CPU 사용 시간은 각 프로세스가 처리되는 데 필요한 시간을 의미한다. 각 프로세스가 처리되는 동안 다른 프로세스들은 대기해야 할 것이다. 만약 각 프로세스들이 대기하는 평균 시간이 길다면 해당 준비 큐에겐 비효율적인 정책일 것이다. 대기 시간은 다음과 같이 간단하게 구할 수 있다.

우선 P1은 첫 번째 프로세스이므로 대기하지 않고 바로 선택되어 실행된다. 따라서 P1은 0초의 대기 시간을 가진다. P2는 P1이 종료될 때까지 대기하므로 16초를 기다린다. P3는 P1과 P2 모두 종료될 때까지 기다려야 하므로 22(16+6)의 대기 시간을 가진다. 평균 프로세스의 대기 시간은 다음과 같다.
(0+16+22) / 3 = 대략 12.7초다.
위 준비 큐에선 CPU 사용 시간이 제일 많은 프로세스가 가장 먼저 처리되므로, P2와 P3 같은 프로세스는 사용 시간이 짧음에도 오래 기다려야 하는 비효율적인 특징이 있다. 이처럼 CPU 사용 시간이 짧은 프로세스들을 오랫동안 기다리게 하는 것을 호송 효과(convoy effect)라 한다. 물론 등록된 프로세스들의 순서가 역순이었다면 보다 평균 대기 시간이 짧아진다. 이처럼 FCFS 정책은 준비 큐에 등록된 순서마다 편차가 다를 수 있지만, 좋은 조건이 보장되지 않기 때문에 호송 효과로 인한 평균 대기 시간이 길어질 수 있다는 단점이 있다.
[순환 처리 스케줄링(RR)]
순환 처리 스케줄링 정책은 모든 프로세스에 CPU 할당 시간을 부여하여 CPU 사용 시간을 제한하는 시분할 시스템(time-sharing system)을 위해 개발된 선점 방식의 스케줄링 정책이다. 따라서 RR 스케줄링 정책은 모든 프로세스에 적절한 CPU 할당 시간을 부여한다. 그리고 준비 큐에 등록된 순서대로 프로세스를 처리한다. 만약 할당된 시간을 모두 사용하였을 경우 다음 차례의 프로세스에 의해 선점되고, 선점된 프로세스는 준비 큐의 맨 뒤에 등록되어 자신의 차례를 기다린다.
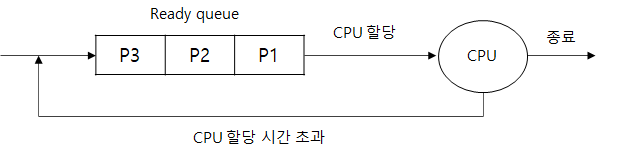
RR 스케줄링 정책에선 각 CPU 할당 시간이 너무 많으면 FCFS 정책과 같이 호송 효과가 발생할 수 있으며, 적으면 빈번한 context switch로 인한 오버헤드가 발생할 수 있다. 때문에 해당 정책에선 적절한 CPU 할당 시간 분배가 중요하다.
[다단계 피드백 큐 스케줄링]
다단계 피드백 큐란 다단계 큐라는 정책에서 피드백(특정 동작)이 추가된 정책이다. 다단계 큐는 지금까지 1개의 준비 큐를 사용한 것과는 다르게 여러개의 준비 큐를 사용한다. 그리고 다음과 같이 준비 큐들 사이에 우선 순위를 부여한다.
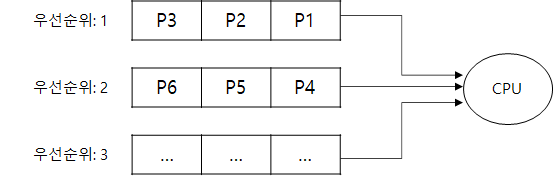
위 3개의 준비 큐 중 가장 우선순위가 높은 큐는 첫 번째 큐이다. 각각의 큐 안의 프로세스는 모두 같은 우선순위를 가지고 있으며 순서대로 처리된다. 따라서 두 번째 큐에 들어 있는 프로세스들은 첫 번째 큐가 비어야만 실행될 수 있다. 만약 세 번째 큐의 프로세스가 실행되는 도중 우선순위가 높은 큐에 프로세스가 생성되면 우선순위가 낮은 프로세스는 높은 프로세스에 의해 선점된다.
이러한 방식의 문제점은 계속해서 우선순위가 높은 프로세스가 들어오면, 우선순위가 낮은 프로세스는 무한정 대기만 하여 절대 실행되지 않는 현상이 발생할 수 있다. 이러한 현상을 기아(Starvation)라 하고, 이러한 현상을 처리하는 기법을 에이징(aging)이라 한다.
이와 같은 다단계 큐의 문제점을 고려하여 피드백을 추가한 정책이 다단계 피드백 큐이다. 다단계 피드백 큐에선 우선순위가 높은 큐에는 상대적으로 적은 CPU 할당시간을, 우선순위가 낮은 큐에는 상대적으로 많은 CPU 할당시간을 부여한다. 그리고 초기엔 모든 프로세스를 첫 번째 큐(우선 순위가 가장 높은 큐)에 등록하여 차례대로 실행한다. 만약 실행 중인 프로세스가 주어진 CPU 할당시간 내에 종료되지 않을 경우 다음 차례의 프로세스에 의해 선점된다. 이때, 선점된 프로세스는 동일한 큐의 맨 뒤에 등록되는 것이 아닌 한 단계 낮은 우선순위의 준비 큐에 등록된다. 이처럼 많은 CPU 사용 시간을 요구하는 프로세스들은 점점 낮은 단계의 큐로 이동된다.

결국 우선 순위가 높은 큐엔 입출력 위주의 프로세스와 같은 CPU 사용 시간이 짧은 프로세스가 주로 머물게 되고, 우선 순위가 낮은 큐엔 계산 위주의 CPU 사용 시간이 긴 프로세스가 주로 머물게 된다. 따라서 해당 정책은 계산 위주의 프로세스보다 입출력 위주의 프로세스가 상대적으로 유리하다.
위 그림처럼 우선 순위가 낮을 수록 많은 CPU 할당 시간을 가진다. 우선 순위가 가장 낮은 준비 큐는 우선 순위가 높은 프로세스가 생성되면 선점되기 때문에 무한대의 시간을 가지고 CPU를 독점할 수 있다. 물론 해당 정책에서도 우선 순위가 높은 프로세스가 계속 생성되어 기아 현상이 발생할 수 있지만, 이를 위해 너무 오래 대기한 프로세스를 우선 순위가 높은 큐에 옮기는 에이징 기법이 존재하므로 걱정하지 않아도 된다. 참고로 이와 같은 다단계 큐 방식에선 각각의 큐마다 다른 스케줄링 정책을 적용할 수 있기 때문에 각 시스템의 용도별로 우선순위를 나눌 수 있다.
이외에도 CPU 사용 시간이 제일 짧은 프로세스를 가장 먼저 처리하는 SJF 스케줄링, 각각의 프로세스에 우선순위를 부여해 선택하는 우선순위 스케줄링 등이 존재한다.
'CS 기초 > Operating System' 카테고리의 다른 글
| Lock 기반 알고리즘의 문제점 (0) | 2021.09.29 |
|---|---|
| [OS] 운영체제 연습 문제 풀이 (2) (0) | 2020.11.07 |
| [OS] 프로세스(Process)에 관하여 알아보자 (0) | 2020.05.31 |
| [OS] 운영체제 연습 문제 풀이 (1) (0) | 2020.05.25 |
| [OS] 운영체제의 구조와 역할을 간단하게 알아보자 (0) | 2019.11.27 |



댓글